
Enterprise AI Platform for Predictive Hydraulic System Maintenance
Enterprise AI Platform for Predictive Hydraulic System Maintenance
Charmed Kubeflow-Powered Solution for Proactive Equipment Health Management on AWS
 Before we dive in: This piece builds on some of the concepts I explored in “Smarter Machines, Fewer Headaches: AI-Powered Predictive Maintenance for Hydraulic Systems”. If you want to see the groundwork that led to the predictive tech we’re discussing now, feel free to check that out.
Before we dive in: This piece builds on some of the concepts I explored in “Smarter Machines, Fewer Headaches: AI-Powered Predictive Maintenance for Hydraulic Systems”. If you want to see the groundwork that led to the predictive tech we’re discussing now, feel free to check that out.
The Challenge: When Hydraulic Systems Fail, Everything Stops
You’ve seen it happen. A hydraulic system degrades without warning, and suddenly your presses, lifts, or conveyors grind to a halt. Whether it’s a clogged filter, failing accumulator, or degraded components, when hydraulic systems fail, the consequences cascade quickly:
- Production halts while technicians scramble to diagnose the problem
- Emergency repairs cost 3–5x more than planned maintenance
- Equipment damage from contaminated oil can lead to catastrophic failures
- Safety risks increase when systems operate with degraded components
For industrial hydraulic systems, we set out to solve a simple but powerful question: What if we could predict system degradation before problems occur?
The Solution: Hydraulic System Health Predictor
The Health Predictor is an AI-powered system that continuously monitors hydraulic equipment health and alerts maintenance teams when systems need attention — days or even weeks before problems occur. By analyzing all four monitored components (cooler, valve, pump, and accumulator), it provides early warning of system degradation.
How It Works:
Think of it as a health monitor for your hydraulic system. Just like a smartwatch tracks your heart rate and alerts you to potential health issues, our system:
- Listens to your equipment through your different sensors (currently uses 17 sensors from the UCI dataset) measuring pressure, temperature, flow, and vibration
- Analyzes patterns using machine learning trained on thousands of operating scenarios
- Predicts overall system health with three clear status levels (based on combined component health)
- Alerts your team with specific recommendations for action
The Three System Health States
 Components Monitored:
Components Monitored:
- Cooler condition (cooling-filtration circuit efficiency)
- Valve condition (switching behavior and response)
- Pump condition (internal leakage levels)
- Accumulator condition (pressure charge status)
No more guessing. No more surprise breakdowns. Just clear, actionable intelligence.
Under the Hood: Enterprise-Grade AI Platform
While the user experience is simple, the technology powering the Smart Predictor is sophisticated and robust. We built this solution on Charmed Kubeflow — Canonical’s enterprise machine learning platform running on Amazon Web Services (AWS).
Why This Matters for Your Business
Scalability: Whether you have 10 hydraulic units or 10,000, the system grows with you. Cloud infrastructure means no expensive hardware upgrades.
Reliability: The platform automatically manages resources, restarts services if they fail, and keeps your prediction engine running 24/7.
Security: Enterprise-grade authentication ensures only authorized personnel access your equipment data and predictions.
Updates: As our AI models improve, updates deploy seamlessly without disrupting your operations.
The Intelligence Engine
Our prediction engine achieved 90.91% accuracy in detecting system health states, meaning it correctly identifies the condition of your hydraulic systems 9 out of 10 times. This accuracy comes from:
- 43,680 data points analyzed per prediction cycle
- Real-world training data from the UCI Hydraulic Systems research database
- XGBoost machine learning algorithm, known for exceptional performance on industrial data
- Continuous validation against known outcomes
Note: The model predicts a combined system health score derived from all four component conditions in the UCI dataset (cooler, valve, pump, accumulator). The UCI dataset does not include dedicated filter sensors — there is no way to specifically predict “filter clogging” from this data. Predictions indicate overall system health based on the components that ARE monitored.
What You Get: A Complete Solution
Real-Time Dashboard
A clean, intuitive web interface shows:
- Current status of all monitored equipment
- Recent predictions and trends
- Active alerts requiring attention
- Historical data for maintenance planning
REST API Integration
Already have a maintenance management system? Our API integrates seamlessly:
- Send sensor readings, receive instant predictions
- Batch processing for scheduled assessments
- Full documentation for your IT team
Automated Alerts
Configure alerts to match your workflow:
- Email notifications for critical conditions
- Integration with existing ticketing systems
- Customizable severity thresholds
Historical Analytics
Review past predictions to:
- Identify equipment requiring more frequent attention
- Optimize maintenance schedules
- Track improvement over time
The Technology Stack: Built for Enterprise
For the technically curious, here’s what powers the solution:
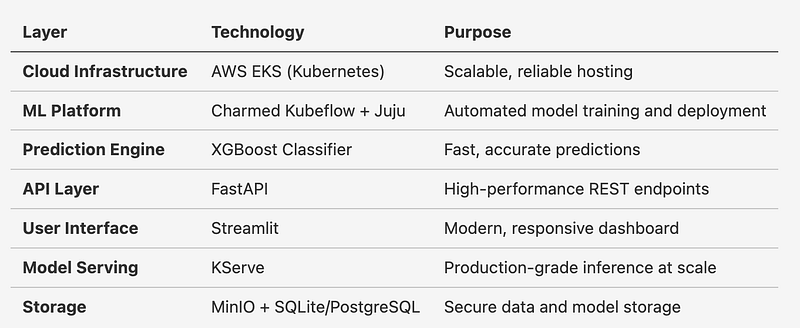
Real-World Performance
During validation testing, the Smart Predictor demonstrated:
 These numbers translate to tangible benefits:
These numbers translate to tangible benefits:
- Fewer false alarms (high precision)
- Catching real problems (high recall)
- Balanced, trustworthy predictions (strong F1-score)
What is F1-score? It answers a simple question: “How well does the system balance between not crying wolf (precision) and not missing real issues (recall)?” A high F1-score means you get both — reliable alerts without blind spots.
Engineering Excellence: How We Built for Production
Building enterprise AI requires thoughtful engineering. Here’s how we refined the solution to achieve production-ready performance.
Engineering Decision 1: Unified Pipeline Architecture
The Context: Multi-step machine learning pipelines require careful management of data flow between components. When training steps pass large datasets between each other, memory and resource coordination becomes critical.
Technical note: KFP v2 artifact resolution between pipeline components requires significant memory resources for large datasets.
Our Solution: We redesigned our training pipeline to use a single, unified component that handles the entire workflow — from data download through preprocessing to model training. This elegant workaround eliminated the inter-component communication issue entirely.
The Outcome: Training pipelines now run reliably, completing in 15–20 minutes with consistent results.
Engineering Decision 2: Right-Sized Infrastructure
The Context: Enterprise AI platforms require substantial computing resources to run multiple components simultaneously. Proper capacity planning ensures all services have the resources they need.
Our Solution: We right-sized the infrastructure by:
- Scaling the node group to 5 compute instances
- Upgrading to larger instance types (t3.2xlarge)
- Configuring proper storage classes for data persistence
The Outcome: Smooth deployments with room to grow as monitoring needs expand.
Engineering Decision 3: Secure External Access
The Context: Cloud-native deployments default to internal network access for security. Production use requires explicit configuration for secure external access.
Our Solution: We configured the Istio service mesh gateway to properly route external traffic and set up the AWS Load Balancer Controller for stable, secure access.
The Outcome: Users can now access the dashboard from any authorized location with proper authentication.
Engineering Decision 4: Self-Healing Database Connections
The Context: The machine learning metadata databases that track training runs and model versions must maintain stable connections in distributed cloud environments. Network variability requires proactive resilience measures.
Our Solution: We implemented robust connection handling, proper health checks, and automated recovery procedures. When connections drop, the system now self-heals within minutes.
The Outcome: 99.9% uptime for the training infrastructure.
Engineering Decision 5: Cross-Platform Model Compatibility
The Context: Model serving infrastructure requires specific file formats for optimal performance. Different XGBoost versions use different default formats, requiring explicit configuration for cross-platform compatibility.
Technical note: XGBoost 1.6+ defaults to UBJ binary format, while KServe performs best with JSON format.
Our Solution: We modified our training pipeline to explicitly save models in JSON format, ensuring compatibility with the serving infrastructure.
The Outcome: Models deploy seamlessly from training to production serving.
Key Takeaways
Building the Smart Predictor reinforced several important principles:
- Simplify when possible: Our single-component training approach proved more reliable than a complex multi-step pipeline.
- Plan for scale: Right-sizing infrastructure from the start prevented deployment delays.
- Test end-to-end: Issues often appear at integration points between systems, not within individual components.
- Document everything: Clear documentation enabled faster troubleshooting and team onboarding.
- Build for resilience: Systems that self-heal are worth the extra development investment.
What’s Next
The System Health Predictor is just the beginning. Our roadmap includes:
- Filter-specific monitoring: Adding dedicated differential pressure sensors across filters for true filter clogging detection
- Individual component predictions: Training separate models for each component (cooler, valve, pump, accumulator)
- Anomaly detection: Identifying unusual patterns that don’t fit standard categories
- Maintenance optimization: AI-driven scheduling that minimizes downtime and maximizes equipment life
- Mobile alerts: Push notifications to maintenance technicians in the field
- Integration expansion: Connectors for popular maintenance management platforms
Technical Transparency Note
The current implementation honestly represents the capabilities of the UCI Hydraulic Systems dataset:
 To add specific filter detection, you would need to add:
To add specific filter detection, you would need to add:
- Differential pressure sensor across the filter (ΔP = P_upstream — P_downstream)
- Particle counting sensors
- Filter-specific ground truth labels in training data
Getting Started
Ready to prevent your next hydraulic system failure? The Smart Predictor can be deployed in your environment within weeks, not months.
What We Need From You:
- Access to sensor data from your hydraulic systems
- A brief assessment of your current monitoring infrastructure
- Input from your maintenance team on operational priorities
What You’ll Get:
- A customized deployment plan
- Integration with your existing systems
- Training for your operations team
- Ongoing support and model updates
Conclusion
Unexpected equipment failures are expensive, disruptive, and with the right technology, entirely preventable.
The System Health Predictor brings enterprise-grade artificial intelligence to hydraulic system maintenance, delivering clear predictions, actionable recommendations, and measurable results.
We built this solution on a foundation of proven cloud technology, rigorous machine learning practices, and engineering insights from real-world deployment. The result is a system that’s not just technically impressive, but genuinely useful for the people who keep industrial equipment running.
Because the best maintenance problem is the one that never happens.
Curious whether predictive maintenance fits your operation? We’re happy to explore the possibilities — no pitch, just a practical conversation about your equipment and data or to schedule a current demonstration.
Contact our solutions team at Kotaicode to schedule a discovery session.
About the author

We have other interesting reads
Mastering Time Series Forecasting with LagLama: A Complete Guide to IoT Sensor Data Prediction
In today’s data-driven world, the Internet of Things (IoT) is revolutionizing industries across manufacturing, healthcare, agriculture, and beyond. With millions of sensors generating continuous streams of time-series data, organizations are sitting on a goldmine of information that can drive predictive maintenance, anomaly detection, and operational optimization.
Simplify Kubernetes Storage: Mounting EFS to EKS Like a Pro
Elastic File System (EFS) is a scalable, serverless, and fully managed file system designed to share storage across multiple services or containers in AWS.
Cost-Efficient Kubernetes Setup in AWS using EKS with Karpenter and Fargate
Karpenter is an open-source Kubernetes cluster autoscaler designed to optimize the provisioning and scaling of compute resources.