
How AI-Powered Fraud Detection Works: A Business Leader’s Guide
How AI-Powered Fraud Detection Works: A Business Leader’s Guide
Understanding the technology that protects billions in transactions every day

The Growing Challenge of Transactional Fraud
Fraudulent transactions, whether from credit cards, debit cards, digital wallets, or other payment methods, cost businesses billions of dollars annually, and the problem is getting worse. As digital transactions increase, fraudsters become more sophisticated. Manual review of transactions is simply impossible when processing thousands, or millions, of transactions per day.
This is where artificial intelligence and machine learning step in. Modern fraud detection systems can analyze transactions almost instantly, identifying suspicious patterns that would be invisible to human reviewers.
But how do these systems actually work? And what should business leaders understand about implementing them?
What Is Fraud Detection AI?
At its core, fraud detection AI is a machine learning system trained on millions of historical transactions. It learns to recognize patterns that indicate fraud versus legitimate activity.
Think of it like training a security guard who has seen millions of transactions. Over time, they develop an intuition for what “normal” looks like versus what “suspicious” looks like. AI systems do the same, but at a scale and speed humans can’t match.
The Basic Process
When a transaction occurs, here’s what happens:
- Transaction arrives: A customer attempts to make a purchase
- AI analyzes multiple factors: The system examines 30–40 different characteristics simultaneously (transaction time, amount, location patterns, spending history, etc.)
- Risk score calculated: The AI outputs a probability score from 0% to 100% indicating fraud likelihood
- Action taken: Based on the risk level, the system recommends approval, review, or blocking
The entire process happens faster than a human can blink, in real-time, without noticeable delay.
Understanding Risk-Based Decision Making
Modern fraud detection doesn’t just say “fraud” or “not fraud.” Instead, it uses a risk-based approach similar to credit scoring. This graduated system allows businesses to:
- Automatically approve low-risk transactions (reducing operational costs)
- Flag medium-risk transactions for review (balancing security and customer experience)
- Block high-risk transactions immediately (preventing losses)
Typical Risk Tiers
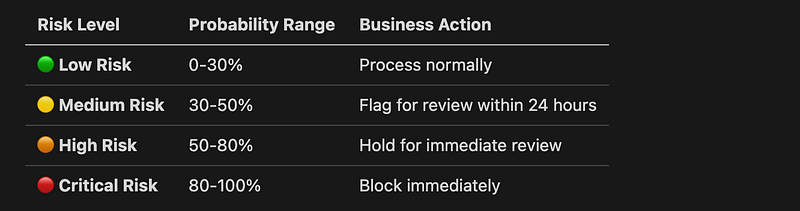 This approach is crucial because it balances three competing priorities:
This approach is crucial because it balances three competing priorities:
- Catching fraud (preventing losses)
- Avoiding false positives (maintaining customer satisfaction)
- Operational efficiency (not overwhelming review teams)
The Challenge of Imbalanced Data
One of the biggest challenges in fraud detection is that fraud is extremely rare. In real-world scenarios, you might see only 1–2 fraudulent transactions per 1,000 legitimate ones.
This creates a problem: if you trained a system to simply predict “not fraud” for everything, it would be correct 99.8 ~ 99.9% of the time, but it would catch zero fraud. That’s why fraud detection requires specialized machine learning techniques designed for imbalanced datasets.
How Modern Systems Handle This
Advanced fraud detection systems use several techniques:
Class weighting: The AI gives more importance to rare fraud cases during training
Stratified sampling: Ensures both training and testing data contain proportional fraud examples
Specialized metrics: Uses metrics like AUC-ROC that evaluate performance independent of the imbalance.(AUC-ROC measures how well the model distinguishes fraud from legitimate transactions across all risk thresholds, making it ideal for imbalanced data)
Feature engineering: Creates additional signals from transaction data (time patterns, amount transformations, etc.)
What Data Do These Systems Use?
Fraud detection systems analyze multiple types of information:
Transaction Features
- Amount: Transaction value and patterns
- Time: Time of day, day of week, seasonal patterns
- Location: Geographic patterns and velocity (impossible travel detection)
- Merchant: Merchant category and history
- Device: Device fingerprinting and behavioral patterns
Behavioral Patterns
- Spending history: Typical amounts, locations, and times
- Transaction velocity: Multiple rapid transactions
- Pattern deviations: Unusual behavior compared to historical norms
Anonymized Features
Many systems also use principal component analysis (PCA) to create anonymized features that capture complex patterns while protecting privacy. These are often labeled as V1, V2, V3, etc., and represent underlying patterns in the data.
Real-World Performance Expectations
When properly implemented, modern fraud detection systems can achieve:
- 99%+ Accuracy: Correctly identifying legitimate and fraudulent transactions
- 80–90% Fraud Detection Rate: Catching the majority of fraud attempts
- <0.5% False Positive Rate: Minimizing customer friction from incorrect flags
What These Numbers Mean
High accuracy means the system is reliable for automated decision-making.
High fraud detection rate means you’re catching most fraud before it costs money.
Low false positive rate means legitimate customers aren’t frustrated by unnecessary blocks.
The key is finding the right balance, aggressive enough to catch fraud, but not so aggressive that it hurts customer experience.
The Technology Behind It
Modern fraud detection typically uses gradient boosting algorithms (like XGBoost) rather than simple rule-based systems. These machine learning models can:
- Handle complex patterns: Identify subtle fraud signals humans would miss
- Adapt over time: Learn from new fraud patterns as they emerge
- Process at scale: Handle high transaction volumes efficiently
- Provide explainability: Offer risk scores and reasoning for decisions
Why Not Just Rules?
Rule-based systems (e.g., “block if amount > $10,000”) are easy to understand but have limitations:
- They can’t detect complex, multi-factor fraud patterns
- They’re brittle, fraudsters quickly learn to game simple rules
- They create too many false positives or miss sophisticated fraud
Machine learning systems can identify complex patterns that simple rules miss. For example: “This transaction is suspicious because it combines an unusual time, location, amount, and merchant category, none of which alone would trigger a rule, but together indicate fraud.”
This technology isn’t theoretical, it’s already powering fraud detection at major companies worldwide.
What Major Companies Use
- Visa uses Advanced Authorization (VAA) with neural networks
- Mastercard uses Decision Intelligence with machine learning
- Stripe uses Radar, an ML-based fraud detection system
- PayPal has been using ML for fraud detection since the early 2000s
The technology itself, machine learning models trained on historical transaction data, is proven and widely deployed.
So What’s Different?
The difference isn’t the technology, but rather:
- Accessibility: Making enterprise-grade fraud detection available to businesses that can’t build it in-house
- Customization: Systems tailored to your specific business patterns, not one-size-fits-all solutions
- Control: Deploying on your own infrastructure with full data ownership
- Transparency: Understanding how the system works rather than using a “black box” service
- Cost-effectiveness: Avoiding expensive third-party services while maintaining enterprise capabilities
In other words, the value isn’t in inventing new technology, it’s in making proven, enterprise-grade fraud detection accessible, customizable, and controllable for businesses that need it.
Privacy and Security Considerations
For businesses considering fraud detection systems, data privacy is paramount. Modern implementations should offer:
- On-premises or private cloud deployment: Data never leaves your infrastructure
- Encryption: All data encrypted in transit and at rest
- Compliance: Designed to meet GDPR, PCI-DSS, and other regulations
- Model ownership: You own and control the trained models
The best systems allow you to train and deploy models entirely within your own Kubernetes infrastructure, giving you complete control over your data and models.
Real-World Benefits
Organizations implementing AI-powered fraud detection typically see:
Financial Impact
- Reduced fraud losses: Every blocked fraudulent transaction is money saved
- Lower operational costs: Automated processing reduces manual review needs
- ROI calculation: For businesses processing $10M annually, preventing 1–2% fraud loss means $100K-$200K saved
Operational Benefits
- 24/7 monitoring: Systems never sleep, catching fraud at all hours
- Scalability: Handle transaction volume growth without proportional cost increases
- Speed: Real-time processing that doesn’t slow down customer transactions
Customer Experience
- Reduced false positives: Legitimate customers aren’t frustrated by incorrect blocks
- Faster processing: Low-risk transactions approved instantly
- Transparency: Risk-based scoring allows for graduated responses
Implementation Considerations
Data Requirements
To build an effective fraud detection system, you need:
- Historical transaction data: Typically 6–12 months minimum
- Labeled fraud cases: Known fraudulent transactions for training
- Sufficient volume: Generally 100,000+ transactions for reliable training
Note: Many organizations start with public demonstration datasets (like transaction fraud datasets with 284,807 transactions) to validate their approach before using production data.
Deployment Options
Modern fraud detection can be deployed:
- Real-time API: Transactions analyzed as they occur
- Batch processing: Analyze transactions in batches
- Hybrid approach: Real-time for high-value, batch for others
The system should integrate seamlessly with existing payment processing infrastructure.
The Future of Fraud Detection
As fraudsters evolve, so must detection systems. Emerging trends include:
- Self-learning systems: Models that continuously adapt to new patterns
- Explainable AI: Systems that explain why transactions are flagged
- Behavioral biometrics: Analyzing typing patterns, mouse movements, etc.
- Graph analytics: Detecting fraud networks and organized crime rings
Key Takeaways for Business Leaders
- Fraud detection AI is proven technology: Not experimental, but production-ready and widely deployed
- It’s about balance: The goal isn’t catching 100% of fraud (impossible), but optimizing the trade-off between fraud prevention and customer experience
- Data quality matters: The system is only as good as the data it’s trained on
- Privacy is achievable: Modern systems can run entirely on your infrastructure
- **ROI (Return on Investment)**is measurable: For most businesses, preventing even 1% of fraud losses pays for the system
- It scales: Once implemented, the system handles growth without proportional cost increases
Conclusion
AI-powered fraud detection is not experimental, it’s the proven industry standard used by major payment processors, financial institutions, and e-commerce platforms worldwide. As transaction volumes grow and fraudsters become more sophisticated, businesses need automated systems that can analyze patterns at scale and speed.
The technology is mature, the benefits are clear, and the implementation options are flexible. For businesses processing significant transaction volumes, the question isn’t whether to implement fraud detection, it’s how to implement it effectively.
About This Analysis
This article is based on real-world implementation experience with machine learning fraud detection systems, including work with transaction fraud datasets (such as the Kaggle Credit Card Fraud Detection dataset with 284,807 transactions) and production deployments on Kubernetes infrastructure.
The principles discussed here apply broadly across industries and payment types, from credit cards and debit cards to digital wallets, bank transfers, and subscription payments. Whether you’re processing card transactions, ACH payments, or digital wallet transfers, the same machine learning approaches can detect fraudulent patterns.
While the core technology is established, the implementation approach (algorithms, infrastructure, data requirements) can be customized to each organization’s needs.
Interested in implementing enterprise-grade fraud detection for your organization? We specialize in production-ready ML systems that run on your infrastructure, giving you complete control over your data and models — the same technology used by major payment processors. Feel free to reach out to discuss your specific use case.
This article provides educational information about fraud detection technology. For specific implementation guidance, consult with ML engineering teams familiar with your infrastructure and compliance requirements.
About the author

We have other interesting reads
Conversational Finance: AI Assistant that talks to your Fund Data
We have been working with VC funds and taxation for sometime, and we thought it is high time we had a new way for fund managers and tax specialists to interact with financial data — naturally, securely, and instantly.
Mastering Time Series Forecasting with LagLama: A Complete Guide to IoT Sensor Data Prediction
In today’s data-driven world, the Internet of Things (IoT) is revolutionizing industries across manufacturing, healthcare, agriculture, and beyond. With millions of sensors generating continuous streams of time-series data, organizations are sitting on a goldmine of information that can drive predictive maintenance, anomaly detection, and operational optimization.
From Proof-of-Concept to Production: Evolving Your Self-Healing Infrastructure
In the previous article, we explored building a self-healing nginx infrastructure using KAgent and KHook, covering autonomous configuration validation, intelligent analysis, and automated remediation.